Unit 2: Develop Algorithms
Contents
Unit 2: Develop Algorithms#
For Unit 2 we are concerned about the development of algorithms for the management of the data store. This process will have to occur after the development of the datastore.
Specifically we will need to create IPO tables for:
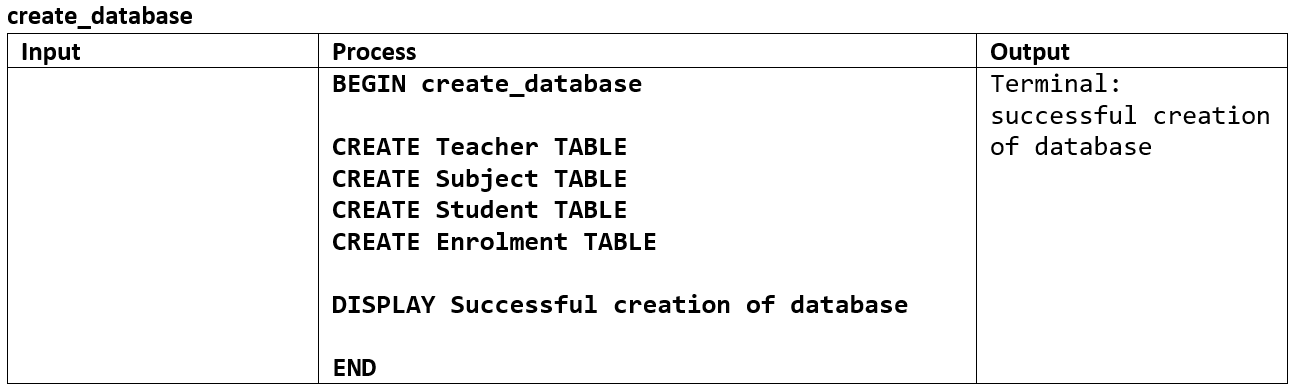
Creating the database
Processing data for insertion
Retrieval of data
Manipulation of data
In writing the pseudocode you can use SQL keywords and methods, but they do not have to be syntactically correct. Like all pseudocode, it only need to be explicit what it wishes to achieve.
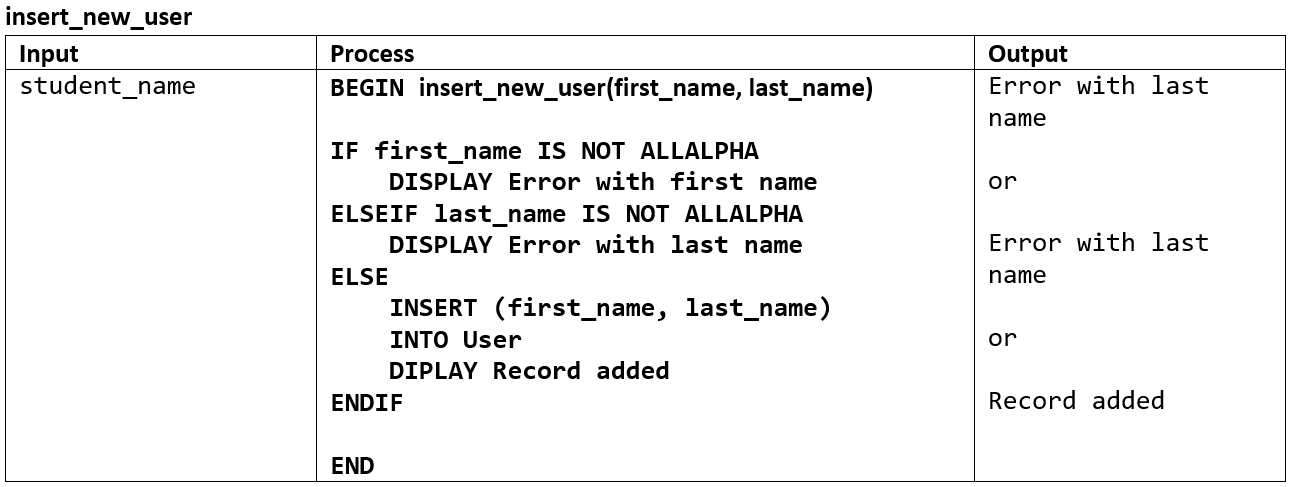
Creating database structure#
The pseudocode for the algorithm developed to create the database should explicitly identify all tables created.
The IPO for the Student Subject Database example would be
Processes data for insertion#
There are two steps in processing your data for insertion.
Cleaning the data
Inserting the data into your database
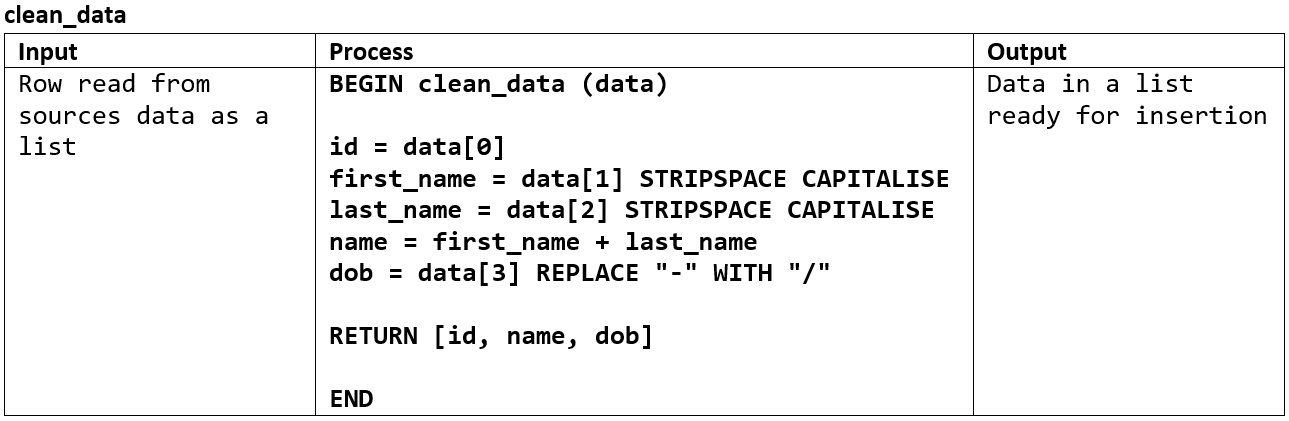
Cleaning the data#
Data cleaning is the process of ensuring that your data is correct, consistent and usable.[Gimenez, 2020]
To clean the data you need to have a close look at the data you have been provided, and identify possible problems with the data. To fix the data manually is not feasible, once the dataset becomes sufficiently large, so you will need to work out an algorithm, which identifies problems and then corrects the data ready for insertion into the database.
Possible errors include:
unnecessary leading or trailing spaces
duplicate entries
incorrect capitalisation
inconsistent values (eg. NA, n/a, not applicable)
missing data
formatting of values (eg date format)
merging or splitting values (eg. name column split into FirstName and LastName)
Your cleaning algorithm will depend on the errors you identify and it is recommended that it is written as a separate function, as it will be called for each line of data that you need to insert
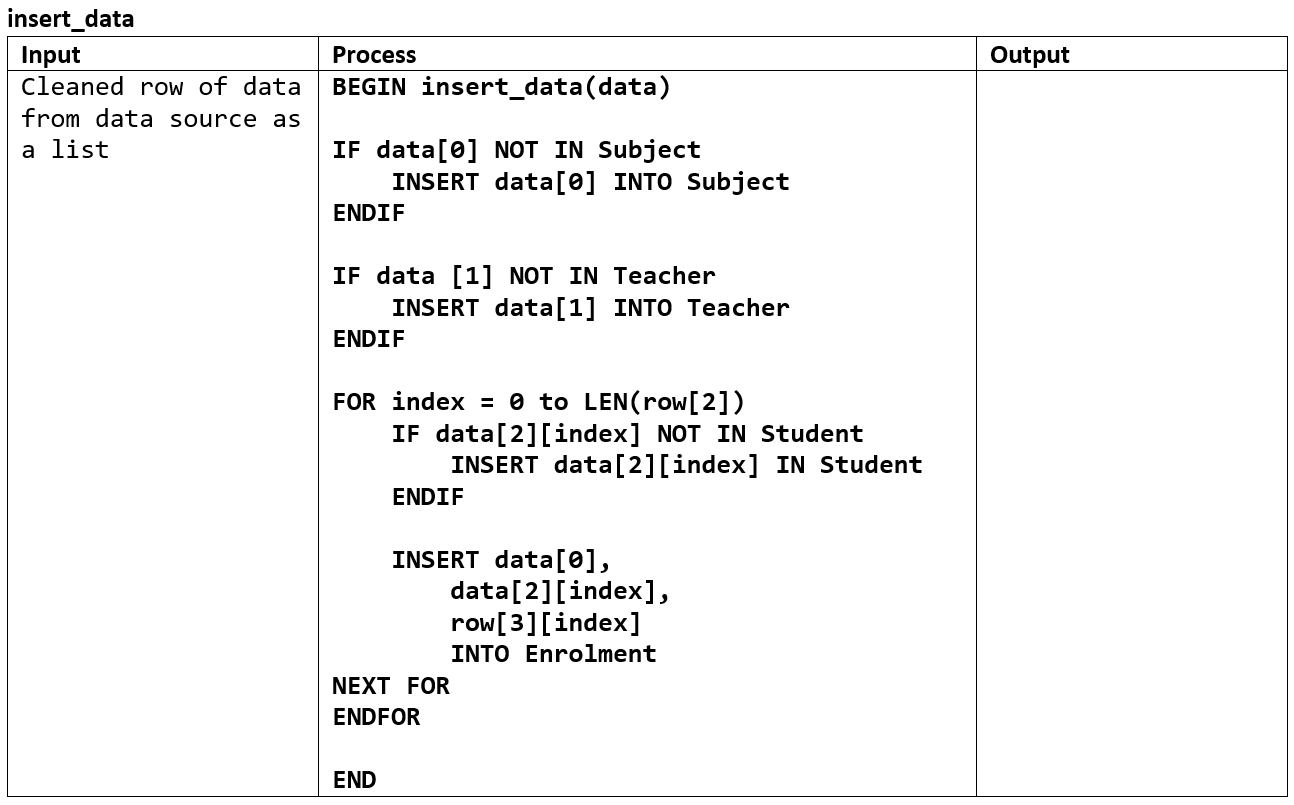
Inserting data into database#
Now that the data has been cleaned it can be inserted into your database. This can get quite tricky, as often data is provided a flat file database and needs to be parse it into a relational database. Why is this tricky? Well, each row of a flat file data source may contain multiple database tables, or, conversely, a single database table my be provided over several rows in the flat file data source.
Your application will read the source data one row at a time, and you will need to assemble the insertion data into the appropriate tables for your database. How this insertion data is assembled will depend on the structure of you database and the data source.
For example, consider the data in this flat file data source:

Your pseudocode would have to address the following issues:
the data contained in the data source will need to be written to four different database tables
there is duplicate data
teacher names
student names
the student column contains a list and each item needs to be processed separately
the results column also contains a list which requires you to assume that the results correspond with the names from the student column
Your IPO could look like this:
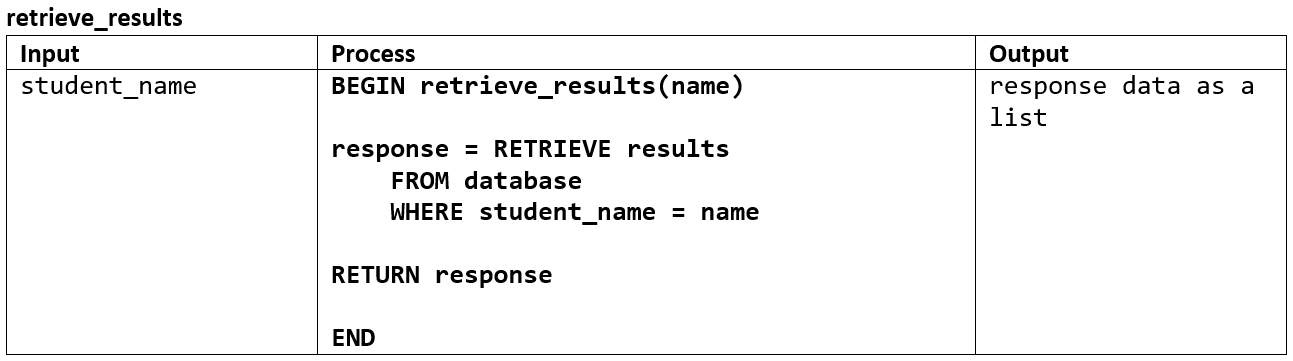
Retrieving data#
In designing algorithms for data retrieval you need to identify what data you want and any limitations of that data.
An example of a data retrieval IPO:
Manipulating data#
Manipulating data involves working with data and then inserting it into the database. This data might originally come from the database, or it may come from another source such as the user.
Before the data can be inserting in the database, it needs to be validated.
An example of a manipulating data IPO: