
Unit 2: Identify Requirements
Contents
Unit 2: Identify Requirements#
In addition to the requirements from Unit 1, you also need to consider
Programming options#
Data models#
Data modeling (data modelling) is the process of creating a data model for the data to be stored in a database. This data model is a conceptual representation of Data objects, the associations between different data objects, and the rules. [Taylor, 2018]
It is defined as an abstract model that organizes:
data description
data semantics
consistency constraints
Data models emphasizes on what data is needed and how it should be organized instead of what operations will be performed on data.
The primary goal of using data model are:
ensuring that all data objects required by the database are accurately represented.
help designing the database at the logical level
defining the relational tables, primary and foreign keys and stored procedures.\
providing a clear picture of the base data and can be used by database developers to create a physical level
identifying missing and redundant data
making IT infrastructure upgrades and maintenance cheaper and faster
In this course we will be creating data models using Entity Relationship models.
Storage#
Data storage requirements can relate to either policies and procedures that need to be adhered to for the safe storage, use and destruction of data and also to the physical and software requirements of storing that information.
The safe storage of data is atopic that will be more closely investigated in Unit 4. For Unit 2 we are concern with storing data in way that ensures:
data integrity
data validity
data reliability
You will need to consider:
Where will the data be stored (locally or remotely on a server)?
What file format will be used to store the data?
How will the data be backed-up?
What security will the data need?
Output requirements#
The problem will have some explicit output requirements. What does the user need the application to provide?
Identifying the output requirements, will help determine the data needed, and identify any missing data.
Data Insertion#
In order to be able to store data into a database there are a number of important processes that need to be followed to make sure that the data that is stored is usable.
These issues can relate to variations in data formats, data structures, validation rules and data requirements.
Data formats#
The storage of data needs to be consistent. That means the way that one data point is stored is the same from record to record. For example 100,000 and \(10^5\) are the same number, but they are formatted differently. Before designing a database and storing data, the accepted format of this data needs to be decided.
Some common data formats that need to be established:
Dates:
dates have the widest range of accepted range of formats
date formatting is represented by:
d: day
m: month
y: year
common date formats (example is 13th August 1984):
dd/mm/yyyy 13/08/1984
dd/mm/yy 13/08/84
d/m/yy 13/8/84
mm/dd/yyyy 08/13/1984 (US date style)
yyyymmdd 19840813
Time:
time of day also has a range of accepted formats
time of day formatting is represented by:
H: 24hr hour
h: 12hr hour
m: minute
s: second
A: AM or PM
common time of day formats (example is 1:15pm)
HH:mm 13:15
hh:mmA 01:15pm
h:mmA 1:15pm
Numbers:
numbers and are often formatted in a specific way (eg. phone numbers and currency) or may be expected to have specific number of places after the decimal point.
numbers formatting is represented by:
0: required digit between 0 and 9
9: optional number between 0 and 9
common number formats:
mobile number: 0000 000 000
landline number: (00) 0000 0000
postcode: 0000
currency: $ 90.00
Data structures#
The two basic data structures that this course deals with are:
flat file databases: information is stored in a single table
relational databases: information is stored in many, interconnected tables
This course will be dealing with relational databased, but the source data may be in a flat file database. Data from flat file databases will have to be parsed to be converted into the form acceptable for the relational database.
Validation rules#
Data can have a limited range of acceptable values. Validation rules restrict data values to within these limitations.
The limitations may be length, types of characters, range of numerical values or more. The data being sourced needs to validated against these limitation before it can be entered into the database.
Examples:
mobile numbers requiring 10 digits
passwords requiring 8 characters or more, at least one uppercase and lower case, at least one digit
the quantity of an item in a sale has to be less than the number of that item in stock
age must be greater than 0
Data requirements#
Before developing a database you will need to identify all the data that will need to be stored in the database. Check that you have access to all the required data and if there is any missing data.
This is vital. Once a database is implemented and in use, it is a painstaking task to make significant changes to the data structure.
Data Management Issues#
Delivering a data-driven digital solution requires a detailed understanding of the data involved. Therefore it is vital to consider the data that underpins the application and issues related to managing that data.
These issues fall under four main categories:
Data acquisition
Data integrity
Data anomalies
Security and protection
Acquisition#
Data acquisition is the process of collecting and capturing data from various sources and converting it into a usable digital format for further analysis and processing. In acquiring the data that will be the foundation of your solution you need to consider both the timeliness of the data acquisition and the ownership of the data.
Timeliness#
Data is a point-in-time measurement, which means there is always a delay between between data creation and dated entry. The impact of data timeliness data depends upon its purpose. A database that records daily temperature has a different timeliness demand than a database that records the core temperature of a nuclear powerplant. Despite both databases recording temperature, a delay of a minute would be of no concern for recording the daily temperature, but could be catastrophic for the nuclear powerplant.
In exploring the data needs of your solution, consider what delay there may be in your data acquisition, as well as, how much delay can be tolerated.
Ownership#
There are three types of data ownership:
Personal data ownership: refers to an individual’s ownership of their personal data, such as their name, address, and contact information.
Corporate data ownership: refers to the ownership of data generated and collected by an organization or company, such as customer data, sales data, and financial data.
Public data ownership: refers to data that is owned by the public or government, such as census data, public records, and government statistics.
It is possible for the data in a database to contain a mix of ownerships. Each type of data ownership has different handling requirements. These will be addressed in Unit 4. For Unit 2 purposes it is adequate to identify the ownership of the data we are working with.
Data Integrity#
Data integrity means that data is accurate, complete, and consistent throughout its lifecycle, from creation and storage to processing and distribution, ensuring that it is trustworthy and not susceptible to unauthorized modification, deletion, or corruption, and is vital in maintaining data quality and reliability in fields such as healthcare, finance, and research.
In analysing the data for your solution you should consider both the current data integrity as well as step you need to take to ensure the integrity of the data once it is entered into your system.
Data integrity depends on the data being:
complete: all data elements are entered correctly and not elements are missing
accurate: the data represents the truth and can be relied upon
kept up to date: all changes to data occurs in a timely manner
consistent: the manipulation of data is completed in a consistent manner
secure: the data is protected from others who may intentionally corrupt it
relevant: the data has meaning and use in the context of your solution
Data Anomalies#
Data anomalies refer to inconsistencies or errors that arise when storing or manipulating data in a database. These anomalies can occur in various forms, such as:
Insertion anomalies: Occur when it is not possible to insert data into a database table without also adding additional, unnecessary data.
Deletion anomalies: Occur when deleting data from a table inadvertently causes the loss of other related data that should have been retained.
Update anomalies: Occur when updating data in a table results in inconsistencies between related data items.
Identifying and resolving these data anomalies is critical for maintaining data integrity in databases and ensuring that the data is accurate, complete, and consistent.
Proper database design, normalization techniques, and data validation processes can help minimize the occurrence of data anomalies. We will learn about these techniques later in this Unit. For the purposes of the Explore phase, the prevention of such anomalies would form a requirement for your digital solution.
Security and Protection#
Security is essential to the success of any information system and the valuable data stored in it.
Threats#
The potential threats to your digital solution include:
malware: software with malicious intent that can infect systems that serve a data-driven application. Malware examples include:
viruses: replicates itself by infecting other files and programs, causing damage to the system and potentially spreading to other devices.
worms: replicates itself and spreads across networks, consuming bandwidth and causing system slowdowns or crashes.
Trojans horses: disguises itself as legitimate software, tricking users into downloading and installing it, and then allowing unauthorized access to the system.
ransomware: encrypts files and demands payment in exchange for restoring access to them.
spyware: secretly monitors user activity and collects personal information, such as login credentials, credit card numbers, and browsing history.
adware: displays unwanted advertisements, often in the form of pop-ups or banners, and may redirect users to malicious websites.
rootkits: allows attackers to gain privileged access to a system, often remaining undetected and persistent even after system reboots or antivirus scans.
data theft and identity theft: major concerns in relation to information systems and data-driven applications. Systems whose security measures become compromised can be mined for values, sensitive and private data.
invasion of privacy: the security of data access and transmission can lead to invasion of privacy as information may be leaked, gathered, and used for blackmail or unsolicited marketing.
Solutions#
Steps can be taken to minimise the risks presented by the potential threats. These include:
user-level access control: a security mechanism that limits the access of users to specific resources or functionalities within a database based on their roles or permissions. User-level access control can protect a database in several ways:
limiting access to sensitive data or functionalities to only those users who have a legitimate need to access them, thus reducing the risk of unauthorized access or data breaches
enforcing policies such as password requirements, access restrictions, or data retention policies, which can help to ensure compliance with regulatory requirements or internal guidelines
monitoring and auditing user activities within the database, such as logins, data queries, or modifications, which can help to detect and investigate potential security breaches or policy violations.
encryption: a process of changing data from human-readable text into text that is indecipherable, and is an important measure to protect sensitive data such as passwords, financial details, personal information, and intellectual property. There are two methods for encryption:
encryption: a two way process where a key is used to scramble and unscramble data. This is used when the data needs to be returned to its original form
hashing: a one way process where a key is used to scramble data. The data cannot be unscrambles, but hashing the same data will always produce the same result. This is generally used with passwords where a password is hashed before being stored. When a user logs in, their entered password is also hashed and the two hashed passwords are compared.
backup and disaster recover: disasters are always made worse by not planning for them. Good database management practices:
regularly backup the database so that it can be restored if it fails.
log data transactions so that committed data changes can be rolled back
Adding to the mind map#
In the Explore Phase you need to consider both programming options and insertion problems and record the identified requirements in the mind map.
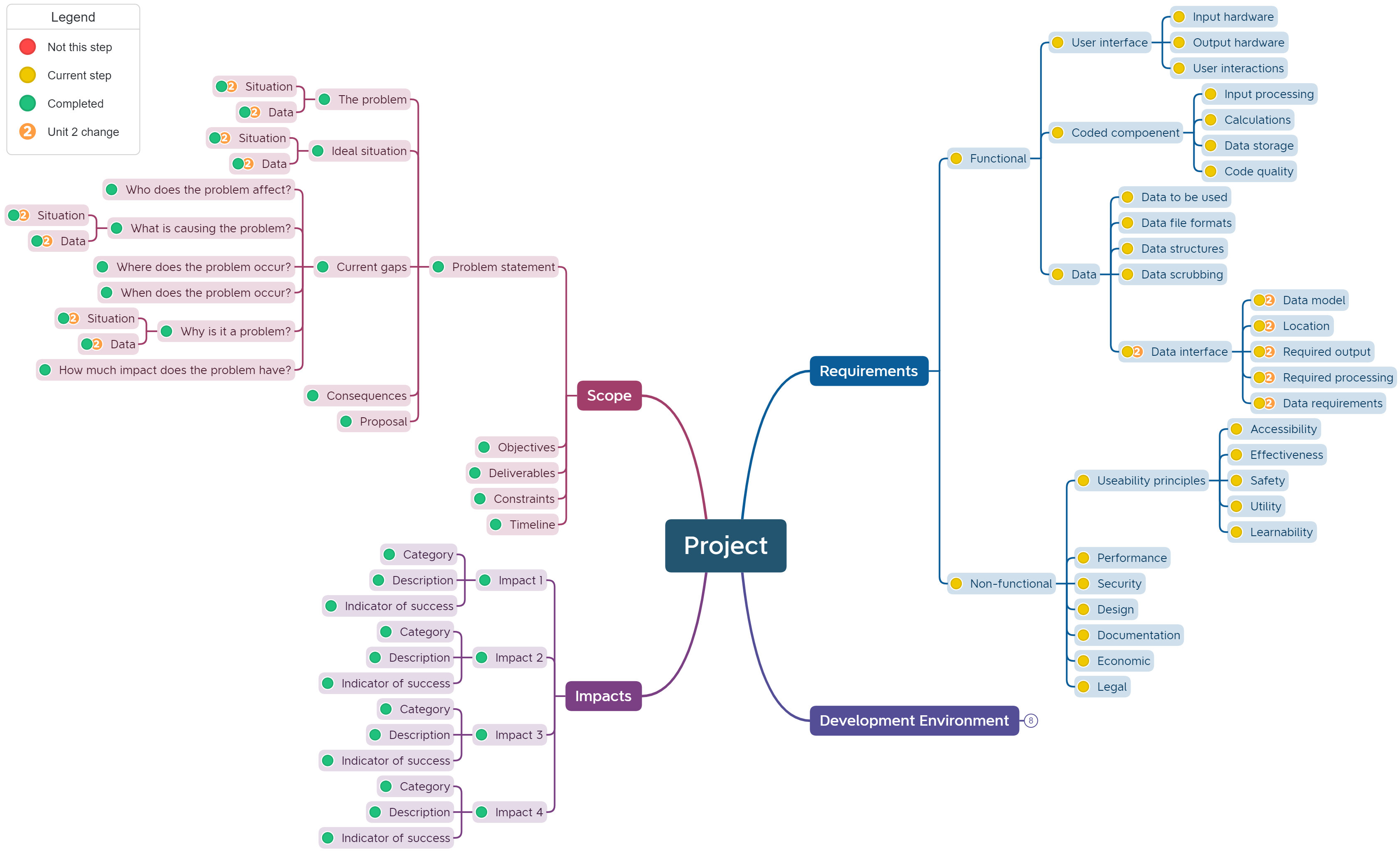
You will need to consider the following issues:
Accuracy: Is the information false?
Completeness: Are there gaps in the data?
Reliability: Is the data contradictory?
Timeliness: Is the information up to date?
Relevance: How applicable is the data to what you’re trying to do?
Availability: Is the data accessible to those who need it?